What I learned after using pihole for a week
In all fairness, it has been more than a week, but due to messing around with logging and accidentally clearing it a few times (whoops!), I didn't have a week worth of data until yesterday.
For the past week, I've been tinkering a bit with Pi-hole, including working with stuff there's no official guides for. There's quite a few things I noticed while messing around with Pi-hole, so I figured I'd write a post about it.
Introduction
For those of you who don't know, Pi-hole is a DNS-based ad/tracker/site blocker. Some third party sites who end up recommending Pi-hole presents it as something "that blocks all ads". This is simply not true, which I'll get back to later. Nonetheless, it still blocks quite a lot, and it extends further than just in browsers. With trackers embedded in a scary amount of software, Pi-hole is most certainly useful. It's just not as versatile as some sites claim it is.Source: research before installing Pi-hole. Not all sites claim this, and others don't mention it at all, but there's very few sites talking about Pi-hole that does mention the downsides.
This post mainly aims to look at the stats, as well as Pi-hole itself. I'm not here to "sell" Pi-hole or convince you to get it. I'm here to share stats, and less commonly mentioned downsides with Pi-hole. So, let's get into it.
Downsides
Before getting into the fun part, let's start with some downsides:
1. Incomplete blocking
Pi-hole is a DNS-based tracker. If it isn't a domain or a subdomain, it can't be blocked. This means it's great for blocking third party trackers, but sneaky companies (looking at you, Google) can sneak in first party trackers as a part of the main domain. For an instance, a tracker script can be stored at https://example.com/tracker.js, which example.com then loads. Pi-hole cannot block this, because it can only block domains or subdomains, by canceling DNS requests. When tracker.js is requested, the browser or whatever makes a DNS request asking for the IP of example.com. If you block example.com, you do block the tracker, but you also disable the entire site. That sneaky embedded tracker stays untouched.
Secondly, there's sneaky companies, again like Google, who make blocking next to impossible in certain cases. One notable example, that loads of people smarter than me have tried and failed at, is ad blocking on YouTube using Pi-hole. I researched YouTube ad blocking with Pi-hole, and found a list (that I unfortunately cannot find again), that had thousands of entries of YouTube subdomains containing ads. So if you're hoping to get Pi-hole to easily block ads in the YouTube app on your phone, you'll be disappointed.
2. False positives
Pi-hole is very straight forward: either it's blocked, or it's not. There's absolutely no exceptions depending on the context, no options to whitelist on certain domains, etc. I've whitelisted Ecosia from my browser-based ad blocker (usually uBlock Origin or Ad Nauseam, which is based on uBlock), but that's the only use I've had for whitelisting so far. I've also had to temporarily whitelist some sites where blocked content completely broke the site. That's a different story though.
If either of these were to happen with Pi-hole as the cause, you have two options: you either live with it, or you whitelist the domain everywhere. If a resource is loaded from a domain Pi-hole blocks, and that resource being blocked breaks the website, whitelisting it in Pi-hole whitelists it on all sites. There's no options to only whitelist it if you're visiting brokensite.example.com.
3. Pi-hole is easy to work around
Being a DNS-based adblocker, doing something as simple as moving advertising sources to a domain that most people won't block makes Pi-hole useless. Fortunately, this isn't currently done on any large scale yet, but if it becomes the standard thing to do, Pi-hole would need to block certain sites entirely to disable tracking.
To take an example that isn't Google (although Google makes a great example), let's do Microsoft Teams. teams itself relies on sources from microsoft.com that can't be blocked without breaking Teams. Many people stuck in quarantine are forced to use Microsoft Teams, so disabling it entirely isn't a choice. my logs show 1923 blocked entries to browser.pipe.aria.microsoft.com. This, presumably along with the mobile.pipe.aria.microsoft.com endpoint is believed to be used for tracking purposes. Now, blocking it with Pi-hole is easy - just blacklist the domains, and you're good to go. But whawt if they move it to microsoft.com instead, under a path instead of a subdomain? To block it, you'd now have to block microsoft.com, which would break teams. Suddenly, Pi-hole is unable to stop the tracker.
There are a lot more examples, and there might be practical reasons that prevent this from actually happening, but if any of the big actors decide to do this, Pi-hole becomes useless.
Summary
While there are various downsides, there's also major advantages when it comes to Pi-hole. Unlike your favorite browser plugin ad-block, it covers the entire device. If you have access to your router (i.e. it's not owned by the ISP), you can even set it to a network-wide DNS and block a lot of nasty trackers. Or you can stick it on your own devices, and leave it at that.
Unless/until Pi-hole becomes less efficient, there are still massive benefits. It's still blocking trackers I didn't know existed, and it's doing a fantastic job on dealing with my Android phone.
Statistics!
Preface
This is arguably the scariest part. Before getting started with Pi-hole, I knew phones and other devices did a lot of tracking, but I had no idea how significant it was until I saw the raw numbers. Before I get into statistics themselves, I'd like to share my setup, and the devices involved in the data produced.
The numbers come from my two devices: my Samsung Galaxy S9, and my MSI computer running Linux Mint 19.3. Linux has some major advantages over Windows, because Windows generally sends a lot more tracking data from the OS itself, some of which can't be disabled. Not running Windows in this period means I don't get to see what would've come out of a Windows computer, and it means traffic from my computer is very low in comparison.
In addition, the browsers on my phone and computer (Firefox on both) runs uBlock Origin. This is mainly to protect from the trackers Pi-hole doesn't stand a chance against, as well as protecting what I can. On my computer, uBlock has blocked a total of 8% of the requests. These 8% are currently equal to just over 72000 requests, and these do, on my computer, reduce the number of DNS queries that go on to get blocked. In fact, the block rate on my computer is significantly lower than the block rate on my phone.
Finally, before continuing onto the numbers, I have to note that I have not used the same blocklists through the entire period. I've added more as I went along, so this list is the final list of blocklists.
https://raw.githubusercontent.com/StevenBlack/hosts/master/hosts
https://mirror1.malwaredomains.com/files/justdomains
https://s3.amazonaws.com/lists.disconnect.me/simple_tracking.txt
https://s3.amazonaws.com/lists.disconnect.me/simple_ad.txt
https://blocklist.cyberthreatcoalition.org/vetted/url.txt
https://adaway.org/hosts.txt
https://v.firebog.net/hosts/Easyprivacy.txt
https://raw.githubusercontent.com/DandelionSprout/adfilt/master/Alternate%20versions%20Anti-Malware%20List/AntiMalwareHosts.txt
https://v.firebog.net/hosts/AdguardDNS.txt
https://raw.githubusercontent.com/matomo-org/referrer-spam-blacklist/master/spammers.txt
https://someonewhocares.org/hosts/zero/hosts
https://v.firebog.net/hosts/Prigent-Ads.txt
https://raw.githubusercontent.com/RooneyMcNibNug/pihole-stuff/master/SNAFU.txt
https://pgl.yoyo.org/adservers/serverlist.php?hostformat=hosts&showintro=0&mimetype=plaintext
https://www.github.developerdan.com/hosts/lists/ads-and-tracking-extended.txt
https://www.stopforumspam.com/downloads/toxic_domains_whole.txt
https://gitlab.com/quidsup/notrack-blocklists/raw/master/notrack-malware.txt
https://gitlab.com/quidsup/notrack-blocklists/raw/master/notrack-blocklist.txt
https://v.firebog.net/hosts/static/w3kbl.txt
https://raw.githubusercontent.com/FadeMind/hosts.extras/master/add.Spam/hosts
https://hostfiles.frogeye.fr/firstparty-trackers-hosts.txt
https://urlhaus.abuse.ch/downloads/hostfile/
https://zerodot1.gitlab.io/CoinBlockerLists/hosts_browser
https://blocklist.site/app/dl/ads
https://blocklist.site/app/dl/crypto
https://blocklist.site/app/dl/youtube
https://blocklist.site/app/dl/tracking
https://github.com/LunarWatcher/Pihole-blocklists/raw/master/global-blocklist-plain.txt
Towards the end of this week of data, I made my own blocklists as well. The last one on the list above is one of them. In addition, I decided to use group management for what it's worth, and made a group for computers and phones. This is still a work in progress, but I applied one blocklist for desktop devices (which just applies to a separate group, and doesn't apply to all devices):
https://github.com/LunarWatcher/Pihole-blocklists/raw/master/desktop-blocklist.txt
All these blocklists yield a total of 418,613 blocked domains, at the time of writing.
The numbers
I'm going to avoid pictures as much as possible, for accessibility purposes. I'm still going to include a few. The first query was made on 11.05.20 at 22:22:36 CEST (+2 GMT), and it's partially on-going while writing this.
At a glance
By querying all the data under long term data in the web dashboard, we get a general overview of the situation. There's 18543 queries blocked, as well as 281 queries blocked through wildcards. This means that out of a whooping 60534 DNS queries, 31.1% were blocked. I mentioned earlier that uBlock Origin's block rate was at 8% with just over 72000 requests since I installed it a really long time ago.

Deep dive: the blocked sites
This is where it gets interesting, but also a bit yucky. Copied from the top blocked domains, queried from the long term data, these are the top blocked sites, along with their cumulative hits in this relatively short period:
Top blocked domains:
semanticlocation-pa.googleapis.com 7437
mobile.pipe.aria.microsoft.com 1644
ssl.google-analytics.com 1139
app-measurement.com 978
app.adjust.com 886
app-analytics.snapchat.com 709
googleads.g.doubleclick.net 481
euw.adserver.snapads.com 456
usc.adserver.snapads.com 371
static.doubleclick.net 319
mobile.pipe.aria.microsoft.com, along with its less used twin browser.pipe.aria.microsoft.com, flood Pi-hole with DNS queries whenever Teams is active. It has NOT been running 24/7, like my phone, but still competes with Google.
Google, ranking #1 on tracking, has nearly 1000 requests per day to semanticlocation-pa.googleapis.com. Purely from the domain, I'm assuming this is related to the location of the device (AKA position tracking). Could be wrong, but it's hard to find out what a closed-source endpoint is for without making some semi-educated guesses.
While the above is all-time, these are for the past 24 hours:
semanticlocation-pa.googleapis.com 974
gstaticadssl.l.google.com 724
fonts.gstatic.com 248
app.adjust.com 161
graph.facebook.com 124
b-graph.facebook.com 122
app-analytics.snapchat.com 117
app-measurement.com 100
mobile.pipe.aria.microsoft.com 88
googleads.g.doubleclick.net 84
The ad count in both of these are heavily underrepresented, thanks to uBlock Origin erasing most of them before they hit the DNS.
Client stats
Client stats are... Interesting, to say the least.
I've intentionally detached myself from my phone, for various reasons. I don't use it a lot, and when I do, but the few times I do, I use it as much as I would use my computer. Net, however, I use my phone a lot less. In spite of that, these are the client stats for the period:
192.168.11.109 (computer) 34152
192.168.11.117 ( phone ) 26106
In spite of using my phone significantly less than my computer with a super satisfying and comfortable mechanical keyboard, it only had 8000 fewer DNS requests. Now, let that sink in. If we subtract all the semantic location attempts (all of which come from my phone - zero of them are from my computer), we're down at 18669 DNS requests. Dropping the 978 app-measurement.com attempts, we're down at 17691 requests. Just from two of the top domains, there's 8415 requests I never explicitly asked for. Even relative to my computer, that is a lot of queries, and a lot of wasted CPU cycles, data, and entropy.
Just for scale, the second domain on the list of top allowed domains, open.spotify.com, made 1118 requests that I actually wanted. My periodic messing around on Pi-hole caused pihole.lan (my internal dashboard URL; see the HTTPS post for context. It's not valid outside my network, in case anyone was wondering :P) has caused that to pop up with 686 requests. 7437 requests in the background, without asking for it, is a lot. Even the sites I visit the most don't get close to that in the pure DNS query count.
Deeper look at mobile traffic
Better yet, here's the rate visualized in the past 24 hours. The net block rate in the past 24 hours has been 31.9% with 2759 blocked queries, out of 8652 total queries.
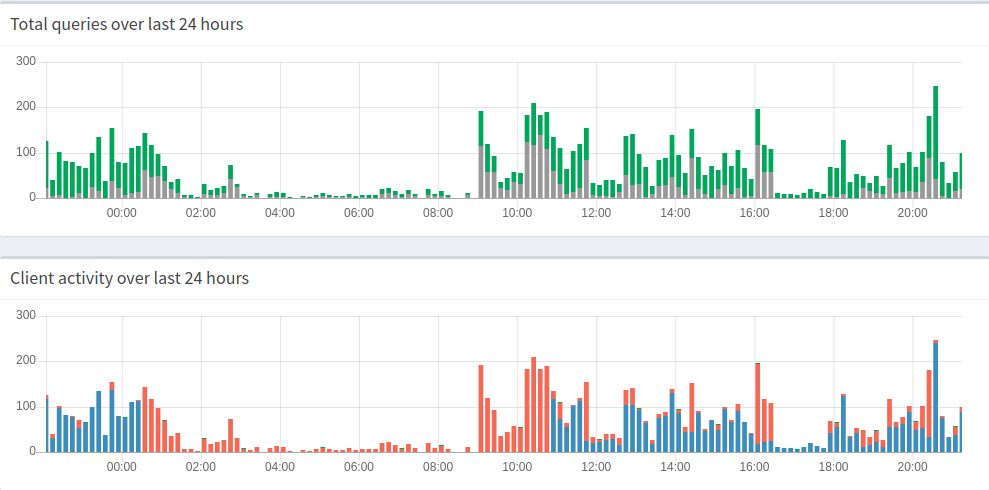
Now, for context, blue is my computer, and orange is my phone on the bottom graph. On the top graph, grey is the amount of blocked queries, and green is the amount of allowed queries. Grey + green is the total amount of requests made in a 10 minute period.
The first thing you might notice is that there's activity at night. There's a tiny bit of DNS activity at night, and you can probably guess where it comes from. That's right, my phone.
At night, my phone makes several completely random queries to, among other things:
- Google Play
- Google ads (?? - I have no idea why)
- Crashalytics (Android crash logging tool; tends to grab more than just the stacktrace)
- connectivitycheck.gstatic.com
- Some Samsung stuff
... Without being explicitly told to do it. I can understand Google Play, connectivitycheck, and update-related Samsung endpoints, but several of these shouldn't be called at all. A major advantage with using any form of ad/tracker blocker is that these are blocked, and could potentially save CPU cycles and power. Other trackers instead spew out requests faster than it most likely would normally. (Of course, there's the question of why I don't block Facebook on my phone, but I have to use it for various stuff. Unfortunately).
Google has given Android app developers a lot of tools for tracking. Google Analytics plugs straight into most apps, and this used to rank a lot higher at night before I removed a bunch of apps I no longer needed, and/or wanted on my phone. Phones, unlike computers, are never truly asleep. At least as long as Linux is running.
Random weirdness: Fake Google domain
For whatever reason, my phone periodically tries to access www.goooooooooooooooooooooooooooooooooooooooooooooooooooooooooogle.com. In my research efforts, I managed to backtrace some of it to Chinese malware, but no anti-malware software actually detects anything. I've not yet been able to figure out what this actually does, or why it's blocked (relevant list), but it doesn't appear to have any constructive uses.
Summary
Some mornings, I sit down and look at the stats for the past night. I some times stumble over domains that haven't made it into any other blocklists, in spite of being rather shady. Using Pi-hole has made me become more aware of how insanely much tracking actually happens, especially on mobile platforms. I knew there was a lot, but I never had any specific numbers on it. If I used Windows actively, I might even have seen higher block stats on my computer. Quite a few of the domains at night really shouldn't run. Facebook doesn't need to update itself at 3 in the morning, Google doesn't need to load analytics... There's a lot of weird tracking behavior in general.
There's also a lot of interesting behavior on certain blocked domains; some programs, when a "necessary" domain is blocked, will attempt to re-request the resource over and over and over. I've been playing some music from YouTube for a couple hours, and uBlock Origin tells me it has blocked 800 trackers. Most of these are just Google Analytics trying to re-request itself because it failed. Interestingly, Pi-hole catches similar behavior. Some reports online[1] also indicate that even Microsoft re-requests blocked domains indefinitely. Gotta love some good irony when a software company worth literally billions don't have a fallback plan, so they just decide to re-request resources until they get it instead.
Google is still among the more aggressive here though, especially on the presumably tracking domain. 7400+ requests in roughly 8 days at the time of writing is pretty impressive. I'd also like to re-visit the disadvantages for one reason: the disadvantages were listed to make it clear that Pi-hole has limitations that are hard to work around. It's often given credit for blocking a lot more than it actually does. It might've been different in the past, but nowadays, it doesn't block everything. In spite of these limitations, it does one hell of a job blocking trackers and ads in most mainstream circumstances.

Comments
Note that all comments are required to follow the code of conduct